多任务
在底层硬件角度上看(这里不考虑多核),所有的任务都是顺序执行,就像流水线一样,然而有些任务会与IO外设交互,IO外设的处理时间一般远大于CPU的指令处理速度,如果让CPU等待这些任务,无疑是一种浪费,因此需要一种提供任务切换的机制,使得CPU不用等待而是继续执行其他任务,当切换得足够快,在用户看来就像多个任务在同时执行。
这个切换机制来自于硬件和操作系统共同实现的异常控制流,包括:
- 中断
- 陷入
- 异常
- 终止
它们使得本来顺序执行任务流发生突变,跳转到对应的异常处理程序。
为了隔离用户任务和操作任务,它们一般工作在不同的空间,拥有的资源操作权限也不同,即所谓的用户态和内核态。
用户任务无法直接操作磁盘,网络等资源,这是内核态才有的权限,因此它们需要向内核申请,操作系统接收这些申请后,需要切换到内核态,然后调用特定的接口(即系统调用),这个切换通常开销很大,通常依赖的是异常控制流中的陷入,与之类似在处理来自IO外设的信号时候,需要进入异常控制流中的中断。
因此,异常控制流提供了底层多任务并发性的基础。
当用户程序调用IO时,存在两个主要性能开销:
- 用户态到内核态的上下文切换
- IO操作本身带来的延时
为了减少这两者对多任务并发性能的影响,需要操作系统和用户程序共同支持。
在操作系统层面,最初,如果一个用户任务要调用IO,那么操作系统会将其阻塞,而用户任务中其他任务不一定依赖IO完成,所以,后来发展出了非阻塞式的IO,非阻塞IO的系统调用会立即返回一个特殊的错误。 基于非阻塞式IO,发展出了IO多路复用技术,也叫事件驱动,在Linux有select,poll,epoll,BSD上的kqueue,本质上它们都有一个类似事件循环的结构,用于查询哪些IO事件已经完成。
在用户软件层面,可以通过进程和线程来调度IO操作,将其分派到子进程,子线程中,为了管理这些子任务,通常也会存在一个类似事件循环的结构,但多线程,多进程也带来了进程通信,线程安全,数据竞争,死锁等问题。
单线程的javascript
js在语言层面并没有线程相关的规范,多线程能力取决于它的runtime,而大部分runtime中js都是单线程执行。
js单线程执行有如下原因:
- js通常被实现为解释执行,而解释执行很难实现真正的多线程能力,PHP,Python也是如此
- 多线程带来的巨大的复杂性,跨线程数据安全,线程管理等
然而,浏览器环境中存在大量的DOM事件,网络请求等耗时的操作,如果同步执行这些任务,将严重阻塞浏览器的对用户操作的响应速度,因此js需要引入异步模型。
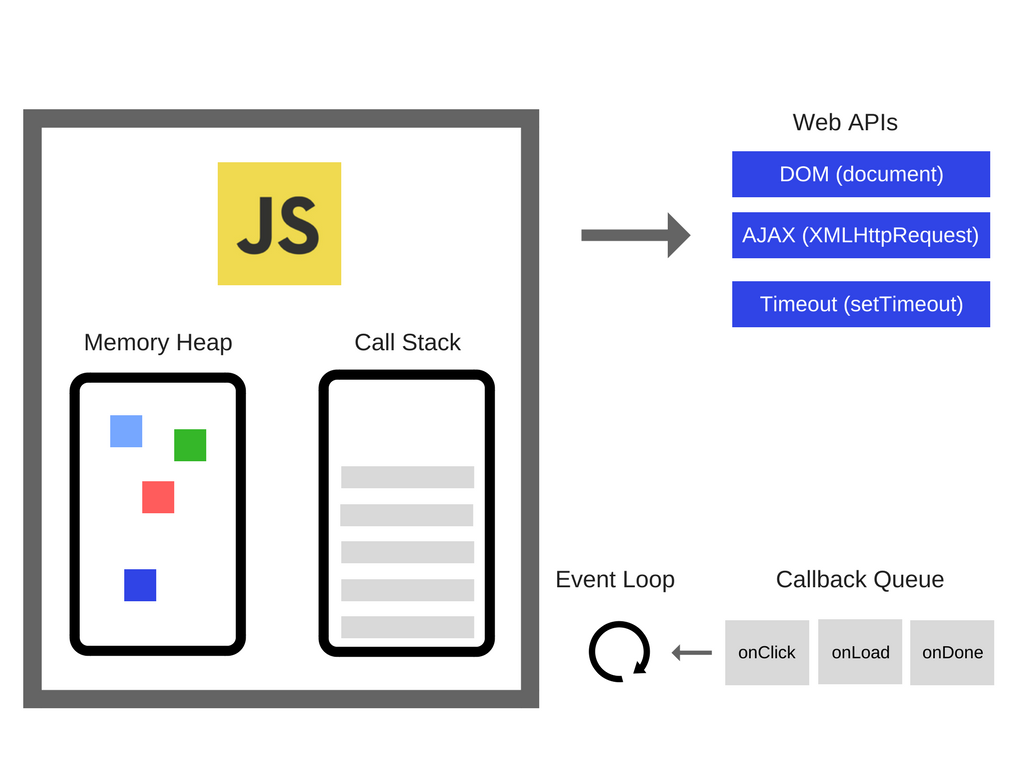
Event Loop
浏览器的event loop实现了单线程上的异步模型 浏览器维护着event loop,本质上是个任务队列,事件,网络请求,定时器,UI渲染,等事件一旦完成它们的回调就会进入任务队列。
v8中实现了默认的event loop,位于src/libplatform/default-platform.cc中的PumpMessageLoop,但允许不同平台覆盖这一实现,比如NodeJS的event loop就是不同的实现
两种不同的task
在w3c以及ES规范中,并没有明确定义microtask,因为这一点实际上是跟语言本身是无关的,本质上是任务调度的问题,具体如何实现需要从实际出发。
不过在WHATWG的规范中有明确microtask:
Each event loop has a microtask queue. A microtask is a task that is originally to be queued on the microtask queue rather than a task queue.
每次event loop都会维护一个microtask队列,当前的loop执行栈空了以后,并且当前macrotask完成以后,会执行microtask队列,直到清空队列,然后进入下一个loop。
microtask的历史,在网上可以查找到的资料是跟 Mutation Obsevers和Object.observe 有关,可以认为microtask的提出是为了实现这两个api。
这两个api都是为了监听对象的变化,因此必须要等待所有的对象变更完毕之后才能执行,即一个macro任务执行完成以后,所以这也是为什么要另起一个microtask任务队列的原因。
从任务调度的角度来看,microtask提供了类似于协程的能力,比如nodejs中的 nextTick 或者浏览器中的 queueMicrotask。