得益于现代化的编译器的底层支持,各种高级语言层出不穷,帮我们这些开发者脱离了晦涩难懂的汇编语言的苦海,可能很多人都看过龙书《编译原理》,但它阅读起来的门槛很高,大部分人半途而废,到底编译器是如何实现的呢?
现代编译器的工作流程包括:
源代码
预处理
编译
汇编
目标代码
链接
可执行文件
其中编译是核心流程,它又包括 词法分析,语法分析,语义分析三个重要流程
语言
语言是一种交流系统,汉语,英语是人类相互交流工具,计算机语言则是计算机和人类之间交流的工具。 不同于汉语英语这种自然语言,计算机语言是通过精确的公式和规则创造出来的,目的是为了让人类更加便捷的指挥计算机工作。语言都有语法,语法是语言学上的概念,自然语言的语法为了便于学习语言而后期研究出来的,计算机语言也有语法,但它是在被创造的时候就设计好了的。
学习英语的过程
举个英语学习的例子,我们从汉语转成英语,会有这样的学习过程
认识26个字母,它们是最小组成部分 然后背单词,它们是最小的语言单位,还会学习是主语,什么是定语,什么是宾语 然后会学习什么是宾语从句,定语从句,什么是是时态 最后我们结合句子所在上下文关系就会理解它的含义 经过这么一个过程,才算入门了英语
从语言学的角度来看,学习所有的语言都可以抽象成下面的几个步骤
- 词法 理解单词
- 语法 理解各种句式
- 语义 理解整段话的含义,需要上下文结合
这个规律同样适用于计算机编程语言 对比下自然语言和计算机语言可以发现如下的相同点
- 都有词汇 比如计算机语言中的各种关键字
- 都有句式 比如循环语句 判断语句
不同点是计算机语言使用环境和目的单一,因此它的词汇量和语句要少得多,翻译起来也简单一点。 看一段代码
var x = 1;
如果要将它翻译成计算机可理解执行的语言,按照上面的方式,需要执行下面几步
认单词:
var 是声明变量的意思
x 是标识符
= 是操作符赋值
1 是一个数字
这一步,可以称为词法分析
那么如何保证这些单词是正确的使用的呢?
计算机语言是按照一定的规范设计出来的,那么我们可以将这些规则都归纳一下,然后就可以判读单词是否正确使用了,比如赋值语句,它的规范是<变量声明><等于号><表达式><分隔符>,类似的,函数声明,流程控制之类的语句都可以总结出规范。
然后用这些规范去检查,保证语句的正确性
这一步,称为语法分析
编译器是如何工作的
词法分析
这是编译的第一步。
每一种语言都有自己特定的关键字,语句,表达式等,比如在js中
var是变量声明的关键字
+,-, *, / || 等等 是运算符
if-else,do-while是循环语句
if-else, switch是条件分支语句
对与计算机来说,源代码只是堆字符,词法分析的作用就是从字符里面提取出一个个单词
字符归类
以js为例,源代码中,只会包含如下的几种单词
- 语言关键字 var, if等
- 分隔符,分号或者换行符
- 标识符,比如变量名,函数名
- 操作符,加减乘除等
- 词法记号 花括号 分号等
- 空格
- 注释符 //,/* */
- 基础数据常量 字符串,数字等
要筛选出这些单词,可以使用正则匹配出来,那么该如何用正则从源代码中查找出所有的单词,这就需要用到有限状态机。
有限状态机
有限状态机是一种模型,用来描述一个系统根据某些输入响应相应的状态,一个典型的有限状态机包括如下部分
- 一个输入集合
- 一个状态集合
- 一个动作集合
- 一个转换函数
- 一个最终状态集合
实现
将有限状态机应用到词法分析上 首先源代码的字符可以作为输入,每个字符都会使得状态机切换到某种状态。 那么接下来的问题是如何建立状态的集合 按照上文对单词的分类,需要参与到最终的编译的只有
- 标识符
- 关键字
- 基础数据常量
- 操作符 其余的 空格,注释,换行,制表符并不参与到最终的代码中,但是编译时也需要处理 现在需要做的是为每种类型都建立自动机
标识符处理
js中标识符只能包含字母或数字或下划线(“_”)或美元符号(“$”),且不能以数字开头。 那么我们可以设置如下的一个自动机
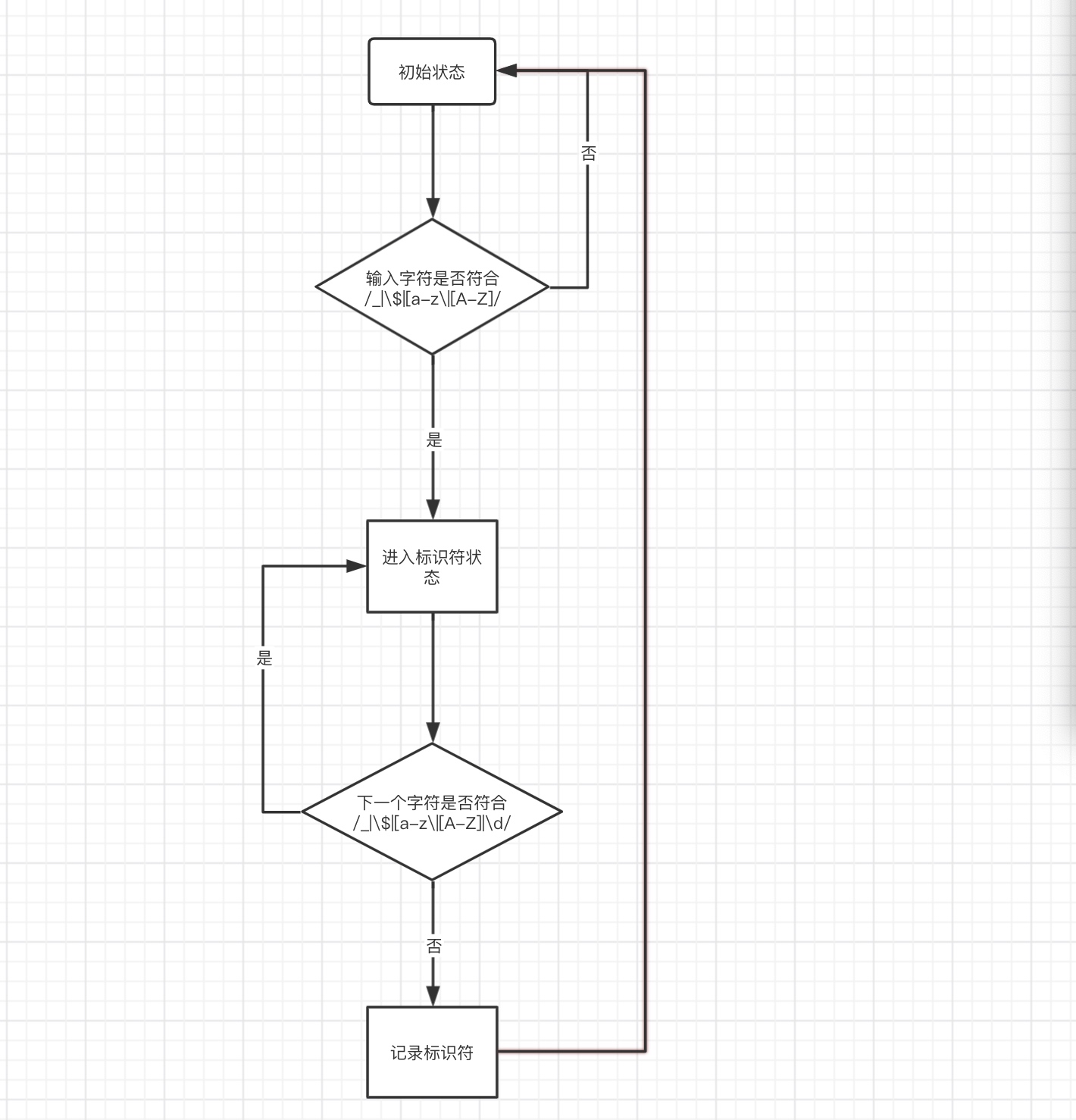
关键字处理
由于js中的关键字个数一定,可枚举,所以可以在标识符处理完以后,检查是不是一个关键字
基础数据常量
js的基础数据类型包括
- 数字
- 字符串
- boolean
- undefined
- null
数字包括二进制,八进制,十进制,十六进制
二进制以0b开头,八进制以0开头,后面跟0-7的数字,十进制是1-9,十六进制是0x开头
可以设计如下的自动机
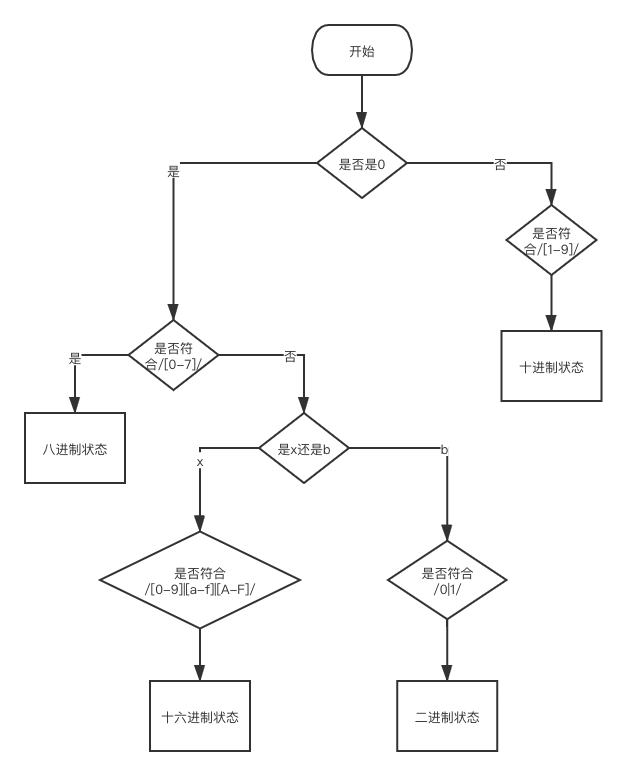
字符串以引号开头,引号结尾,可以设置如下的状态机器(这里没有考虑转义的情况)
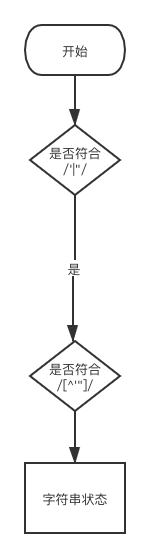
其他
由于界符的形式都是固定的,一一匹配即可,这里不展开讨论
其他还有空格和注释也是需要处理,与上面类似,用正则匹配即可,这里不展开讨论
结果
词法分析完成以后将输出一个单词序列:例如
['var', 'x', '=', 1]
在实际实现中,还会包含单词的类型,以便语法分析的处理